障害復旧とは

障害復旧とは
WEBサービスの運用をしていると、突然動作不良に陥ることがあります。
その時に、取り急ぎ正常な状態に戻すことを障害復旧といいます。「取り急ぎ」と書いたのは、根本原因の解消ではなく、復旧を優先するからです。
復旧方法は大きく分けて2種類あります。
・動作不良の場合
・過負荷の場合
以降でそれぞれの場合の、代表的な復旧方法について解説していきます。
復旧手順

動作不良の場合の復旧方法
何かしらの原因で動作不良となってしまった場合は、再起動で復旧を行います。可能な限り影響範囲が狭い「プロセス再起動」での復旧をおすすめしています。
■プロセス再起動
動作不良を起こしているプロセスを再起動します。
メリットは停止時間の短さと、影響範囲の狭さです。デメリットとしては、インスタンスへのログインが必要になります。問題プロセスの特定や再起動手順など、一定の技術力が必要になります。
■インスタンス再起動
AWSのマネジメントコンソール、またはEC2ログイン後のリブートコマンドにてインスタンスの再起動を行います。パソコンの動作が不安定なときに再起動するのと同じ要領です。
メリットは、ブラウザベースでどこからでも実行できる点です。ただし、相応の時間がかかります。メモリ情報もクリアされてしまうので、起動直後に過負荷となる懸念もあります。

過負荷の場合の復旧方法
アクセス数の増加などの過負荷による障害の場合は、再起動では復旧しないことがあります。その場合は次のように対応します。
■スケールアウト(アップ)
インスタンスの台数を増やす、または上位のタイプに変更することでキャパシティの追加を行います。必要なときに、必要なキャパシティを調達できるのはクラウドを利用するメリットでもあります。AWSではインフラキャパシティを大幅に増やすことができます。ただし、「システム全体のキャパシティ」と考えるとどこかで頭打ちとなります。システムが最初に頭打ちになる原因を事前に把握することが重要です。
■原因排除
過負荷には必ず原因があります。原因を特定し排除することで過負荷の状態から復旧させます。よくあるケースとしては、BOTによるアクセスです。WEBサービスには、人以外にも、BOTのような機械的なアクセスが日常的に発生しています。短時間に集中して望まないBOTがアクセスしてくるケースも多く、BOTのアクセスを拒否するなどして対応します。
復旧方法
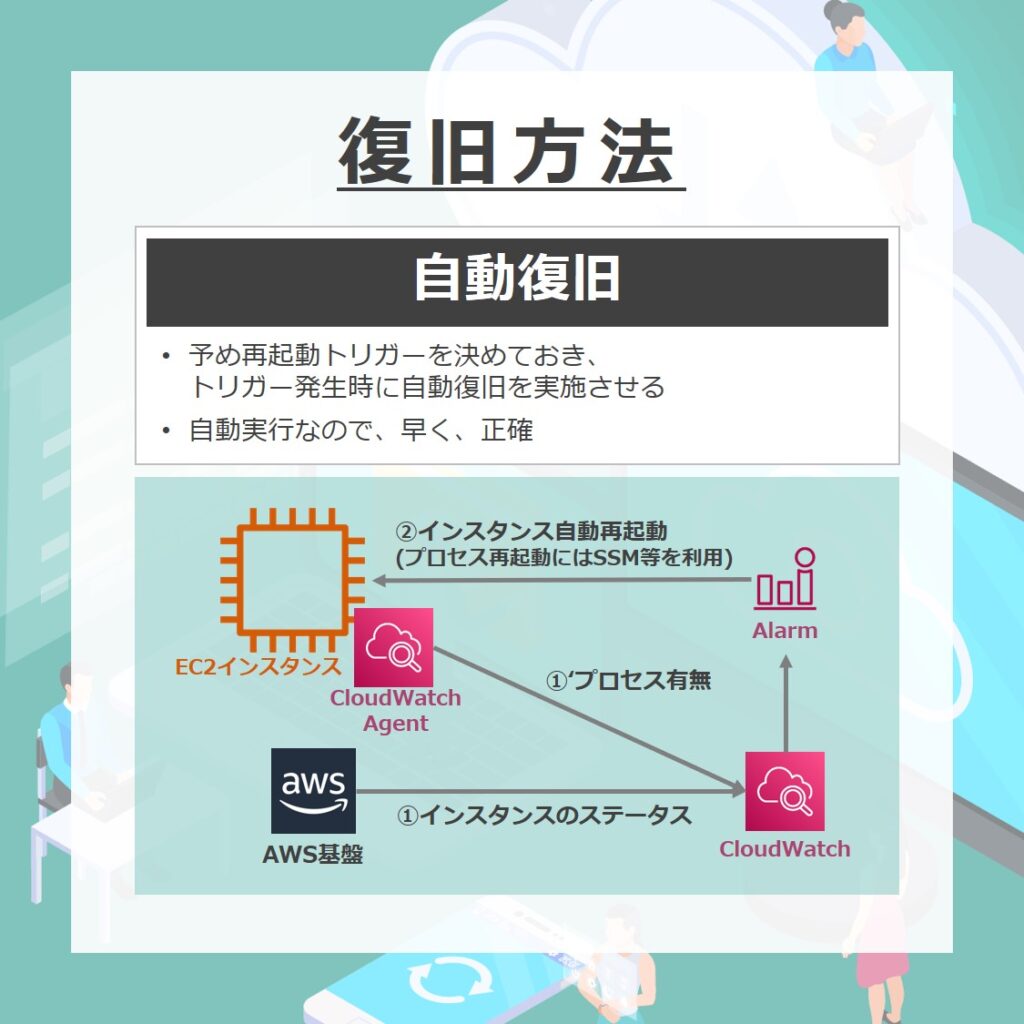
自動復旧
まず初めに検討したいのが自動復旧です。
自動復旧の仕組みを作ることで、いつでも、早く、正確に復旧させることができます。自動復旧では、あらかじめ再起動させるためのトリガーを決めておきます。トリガーが起動したときに行う操作内容についても事前に決めます。
たとえば、CloudWatchを利用した自動復旧を考えます。
CloudWatchで、インスタンスの監視を行います。インスタンス内のプロセス監視を行う場合は、CloudWatchAgentのインストールが必要です。
CloudWatchにて異常を検知した場合はCloudWatch Alarmへ通知しインスタンスの再起動等の操作を実行させます。AWS System Managerを組み合わせることで、プロセス再起動も可能です。

手動復旧
自動復旧が実装できない、事前に想定していなかったため復旧しなかった場合は、手動で復旧させる必要があります。
手動の場合は人によって対応のばらつきが出やすくなります。誰でも一定の品質で対応ができるようにあらかじめ手順書を作っておきましょう。
手動の場合も自動の場合と同様にアラート通知を受けて対応が開始されます。CloudWatchなどの監視システムやユーザーからの問い合わせの場合もあります。
自動復旧ではイレギュラーな事象が発生した場合に対応できませんが、手動復旧の場合は柔軟な対応が可能になります。ただし、対応者のスキルに大きく依存します。
お客様にて障害復旧を行うポイント

お客様にて障害復旧をするポイント
お客様にて障害復旧対応をする場合は、システムの特性に合わせて復旧方法を使い分けてみましょう。
■自動復旧のポイント
自動復旧を行う場合は、事前の準備が重要になります。「想定外」が少なくなるような設計はもちろん、CloudWatchやSSM、AutoScaling、Zabbixなど様々な技術要素を組み合わせることも重要です。また、AutoScalingを使う場合は、正常に対応可能なインフラ環境を事前準備する必要があります。
■手動復旧のポイント
手動復旧を行う場合は、体制構築がポイントとなります。昼夜問わず一定レベル以上の対応ができる体制をいかに構築するかが重要になります。
ディーネットの運用代行サービスでは

ディーネットの障害復旧対応
ディーネットがお客様にかわり、障害復旧対応の代行をいたします。お客様にAWSの技術知識や体制は不要です。
お客様が運用するサービスの特性に合わせて、エンジニアが監視設計から設定、復旧対応まで実施いたします。24時間365日体制のテクニカルサポートが支援するため、昼夜問わず対応します。
また、お客様にて構築しブラックボックス化してしまった環境や、復旧手順書がない場合は、弊社にて復旧手順書の作成を代行も可能です。
関連するFAQ
Q. 障害復旧と原因調査はどちらを優先すべきですか?
A. 一次対応では復旧が最優先です。特に5xxエラー増加やサービス停止が発生している場合は、原因調査よりも先に復旧操作を行い、サービスを安定させた後に詳細調査と恒久対策を実施します。
Q. プロセス再起動とインスタンス再起動はどう使い分けますか?
A. 影響範囲が限定的(特定機能・単一プロセス)であればプロセス再起動、原因不明・広範囲・メモリ異常などの場合はインスタンス再起動を選びます。CPUやメモリの異常値がインスタンス全体に及んでいるかが判断の目安になります。
Q. 過負荷時に再起動で復旧しないのはなぜですか?
A. CPU使用率が高止まりしている、リクエスト数(RPS)が急増しているなど、リソース不足が原因の場合は再起動しても状況は変わりません。スケールアウトやボトルネックの解消が必要です。
Q. 再起動してはいけないケースはありますか?
A. 一時的に処理を保持しているバッチやキュー処理中などは、再起動によってデータ不整合や処理ロスが発生する可能性があります。また、原因が外部依存(DB障害など)の場合は再起動しても再発します。
Q. AWSで自動復旧を実現する方法は?
A. CloudWatchでCPU使用率やステータスチェック失敗、5xx増加などを検知し、CloudWatch AlarmからSystems ManagerやEC2アクションを実行することで自動復旧が可能です。プロセス単位の復旧にはSSMのRun Commandを組み合わせます。
Q. 自動復旧がうまく機能しないのはどんなケースですか?
A. よくあるのは、誤検知による無限再起動、依存サービス(DBや外部API)が復旧していない状態での再起動ループ、しきい値設定が不適切なケースです。監視設計と復旧条件はセットで調整が必要です。
Q. オートスケールが効かない原因は何ですか?
A. スケール条件(CPUやリクエスト数)が適切でない、起動後のアプリ初期化に時間がかかる、ALB配下のヘルスチェックに失敗しているなどが原因として多く見られます。
Q. 手動復旧で品質を保つにはどうすればいいですか?
A. 判断フローと手順書を明文化し、「誰が対応しても同じ判断になる状態」を作ることが重要です。特に夜間対応では、CPU閾値やエラー率など定量的な基準を持たせることで属人化を防げます。
Q. BOTによる過負荷はどのように対処しますか?
A. アクセスログから異常なリクエストパターンを特定し、WAFやセキュリティグループで遮断します。短時間に集中するトラフィックや特定UAの偏りが判断材料になります。
まとめ

最後までご覧いただきありがとうございます
この記事では、AWS上で動かすWEBサービスで発生した障害の復旧手順について解説しました。
障害は昼夜問わず発生します。いつ起きるかもわかりません。
自動復旧や手動復旧など復旧方法はいくつかありますが、いずれも事前に可能な限りの用意をしておくことが重要です。
自社で対応が難しい場合は、ディーネットまでお問い合わせください。24時間365日体制のテクニカルサポートがご支援いたします。