アクセスが急増したとき、「とりあえずスケールすれば解決する」と考えていませんか?実際には、スケールしたのに落ちる、むしろ悪化する、というケースは珍しくありません。原因の多くはシンプルで、「詰まっている場所を見ずに拡張している」ことです。AWSは柔軟にスケールできますが、ボトルネックを外した対策はコストを増やすだけで効果が出ません。
本記事では、CPU・DB・接続数といった典型的なボトルネックの見分け方、メトリクスでの判断ポイント、各サービスの正しい使いどころ(効く/効かない/誤用)までを整理します。さらに、実際に起こりがちな失敗パターンも踏まえて、「落ちない構成」に近づけるための考え方を解説します。
アクセス集中時に発生する事象

要望と特徴をマッチさせる
キャパシティを超えるほどのアクセス集中が発生すると、ユーザーには様々なエラーが返却されることになります。エラーが発生するということは、機会損失が発生するということです。
「504 Gateway Timeout」
サーバー内の処理時間が長すぎる場合に発生します。ELB+Amazon EC2の構成の場合に、EC2インスタンスからの応答が所定の時間を超過した場合によく見られます。
「503 Server Unavailable」
サーバーサイドのどこかで制限がかけられている状態です。レンタルサーバーの利用中に、アクセス集中が発生すると見かけるエラーです。これは、他のユーザーに影響がでないように、サーバーの手前で強制的にエラーを返却しています。
「500 Internal Server Error」
サーバー内部でエラーが発生しています。なんらかのエラーが原因で、正常に処理が行われなかった可能性があります。
アクセス集中対策に有効なサービス

アクセス集中対策の注意点
AWSでは、アクセス集中などの高負荷時に有効なサービスが多数用意されています。
「Amazon EC2 Auto Scaling」
負荷状況に応じてEC2インスタンスを増減させ、キャパシティの確保を自動で行います。アクセス集中の検知から実際の拡張完了まである程度時間がかかりますところに注意が必要です。
「Amazon CloudFront」
EC2インスタンスやELBの前段に配置し、静的なコンテンツを高速にキャッシュ配信します。phpなどの動的なコンテンツは無理ですが、画像などの静的コンテンツの処理負荷をオフロードすることが可能です。
「スケールアップ」
手動対応になりますが、短時間でのインスタンスタイプの向上も可能です。ただし、インスタンスタイプの変更時には再起動が必要になります。
アクセス集中対策の注意点

アクセス集中対策の注意点
アクセス集中対策に有効なサービスを紹介しましたが、使いどころをしっかり押さえる必要があります。誤った使いどころで使ってしまうと、逆に被害が増えてしまう可能性があるので注意しましょう。
使いどころの判断基準は、「ボトルネックに対する対策」になっているか?です。
ボトルネックとは、発生している問題に最も影響している部分のことです。画像の砂時計の砂の落ちる速度を早くしたい、と考えた場合は、ボトルネックになるのは最もくぼんでいる部分になります。くぼんでいる部分の幅を広げることで、砂の落ちる速度を早くすることが可能です。
良かれと思って、底の部分を大きくしたり小さくしたりしても落ちる速度に影響はしません。
対策サービスの効果有無

対策サービスの効果有無
それぞれのサービスはどこがボトルネックになったときに有効なのでしょうか?
「Amazon EC2 Auto Scaling」
EC2インスタンスの数を増減させるサービスなので、CPUなどのリソースが不足している場合に有効な手段となります。逆に言うと、RDSなど、EC2インスタンス以外の箇所がボトルネックとなっている場合には効果を発揮しません。
「Amazon CloudFront」
静的コンテンツをオフロードできるので、WEBサーバーの接続数がボトルネックになっている場合に有効な対策です。反対に、アプリケーションの処理負荷が問題の場合は、有効な対策とはなりません。
「スケールアップ」
Auto Scalingと同様に、CPUやメモリなどのコンピューティングリソースが不足している場合に有効です。設定値の問題で、リソースが使い切れていない場合は効果がありません。
不適切な対策を実施した場合の影響
不適切な対応をした場合の影響
不適切な対応をしてしまうと、どうなるでしょうか?
最も影響が少ないパターンは、「効果が一切出ずに、余計な費用がかかる」パターンです。WEBサーバーがボトルネックなところを、DBサーバーの対策を取ってしまうような場合に発生します。利用料金以外は、良い方向にも、悪い方向にも影響を与えません。
最も影響が大きいパターンは、「悪影響が出たうえに、余計な費用がかかる」パターンです。DBサーバーがボトルネックなところを、WEBサーバーの対策を取ってしまうことで、DBサーバーにより大きな負荷がかかってしまうような場合に発生します。このパターンになると、費用を払って自ら被害を拡大させていることになります。最も避けたいパターンです。
このことから、ボトルネックを把握し、ボトルネックに対する対策を実施することが重要ということがわかります。
対策箇所の特性
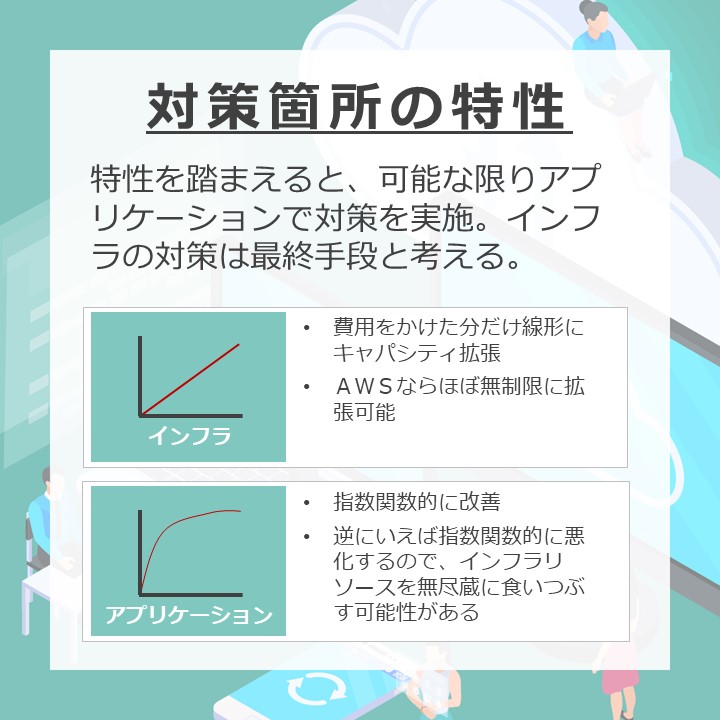
対策箇所の特性
インフラだけでなく、アプリケーション側でも対策を取ることが可能です。インフラとアプリケーションどちらで対策をとる方が好ましい結果になるでしょうか?
「インフラ」
AWSの登場で、費用さえ許容すれば、インフラキャパシティをほぼ無限に拡張することが可能になりました。インフラは費用をかければかけた分だけキャパシティの向上が可能です。vCPUを4から8にすれば、単純に2倍の効果が期待できます。
「アプリケーション」
アプリケーションは処理内容によって、改善効果(悪化の効果)が大きくなります。2重ループをしている場合、データ量が2倍になれば処理負荷は4倍、データ量が3倍になれば9倍の処理負荷となり、指数関数的に性能が変化していきます。
つまり、可能な限りアプリケーション側で対応することで、最終的にはコストパフォーマンスの高い対策が可能になります。
お客様にて運用する場合のポイント

お客様にて運用する場合のポイント
インフラだけでなく、アプリケーション側でも対策を取ることが可能です。インフラとアプリケーションどちらで対策をとる方が好ましい結果になるでしょうか?
「インフラ」
AWSの登場で、費用さえ許容すれば、インフラキャパシティをほぼ無限に拡張することが可能になりました。インフラは費用をかければか高負荷対策を必要なサイトのインフラを運用するポイントは次の2点です。
・ 闇雲なサービス利用はさける
・ 事前シュミレーションをしっかりと行う
闇雲なサービス利用はさける
サービスを理解せずに、やみくもな利用はさけましょう。たとえば、Auto Scalingであれば、ファイル共有方法、ログ管理、セッション管理方法など、実施のために様々な考慮が必要となります。場合によっては、アプリケーション側の改修が必要になることもあります。
事前シュミレーションをしっかりと行う
ボトルネックに対する対策のみが効果を発揮します。事前に最初に発生するボトルネックを把握することで、適切な対策をピンポイントで取ることが可能です。システムのボトルネックは何になるのか?という観点で、負荷テストを事前に実施しておくのが望ましい対応となります。
ディーネットにお任せいただくメリット

ディーネットにお任せいただくメリット
ディーネットでは、負荷テストサービスを提供しております。
負荷テストを実施することで、システムのボトルネックの特定を行うことができます。ボトルネックの特定ができるので、高負荷状態になったときに実施すべき対策を事前把握することが可能です。また、対策実施後のボトルネックがどの程度の性能向上した後に発生するかの把握もできるので、万全な事前準備を行うことができます。
対策を実施するときには、適切なサービス理解が必要です。AWSに精通した負荷対策をとることができるエンジニアも多数在籍しております。そのため、ポイントを絞った形で、適切な対策の実施が行えます。
ローンチ前の負荷テストはもちろん、ローンチ後の高負荷時のトラブル再現等も対応しております。
関連するFAQ
Q. アクセス集中時、まず何を見ればよいですか?
A. ボトルネックの特定です。目安としては以下を確認します。CPU使用率(EC2)、DBコネクション数・CPU(RDS)、同時接続数やスループット(ALB/アプリ)。どれが先に限界に近づいているかで打ち手が変わります。
Q. Auto Scalingで台数を増やしたのに落ちるのはなぜですか?
A. よくある原因はDBボトルネックです。EC2を増やすとリクエストが増え、結果としてRDSの接続数やCPUが先に限界に達します。この場合、スケールアウトはむしろ負荷を集中させる方向に働きます。
Q. CloudFrontはAPIの負荷軽減にも効きますか?
A. 基本的には効きません。CloudFrontはキャッシュ可能な静的コンテンツには有効ですが、キャッシュミス時や動的API処理はオリジンに到達します。API負荷が問題ならアプリやDB側の改善が必要です。
Q. スケールアップとスケールアウトはどう判断すべきですか?
A. 短期的なCPU・メモリ不足ならスケールアップ、継続的なアクセス増や可用性確保ならスケールアウトが基本です。ただし前提として、ボトルネックがコンピューティングリソースであることが条件です。
Q. よくある失敗パターンはありますか?
A. 典型例は「Webサーバー増やしたらDBが落ちた」です。Auto ScalingでEC2を増やした結果、DB接続が急増し、RDSが先に限界到達します。結果として全体停止+コスト増という最悪パターンになります。
Q. 負荷テストでは何を確認すべきですか?
A. 「どこが最初に詰まるか」と「どのメトリクスが先に跳ねるか」です。CPUなのか、DB接続数なのか、レスポンスタイム(レイテンシ)なのかを特定できれば、対策はほぼ決まります。
Q. アプリケーション側でやるべき対策は?
A. 代表例として、N+1クエリの解消、キャッシュ導入(Redis等)、非同期処理化があります。特にDB負荷が原因の場合、インフラよりもアプリ改善の方が効果が大きく、コスト効率も高くなります。
まとめ

AWSの導入、運用はディーネットにお任せ下さい
AWSは、インフラの拡張が非常にしやすいパブリッククラウドです。
適切なタイミングで、適切なサービスを利用することで、インフラのキャパシティをほぼ無制限に拡張することが可能です。しかしながら、不適切なタイミングで、不適切な使い方をしてしまうと、システム全体としてのキャパシティが拡張しないばかりか、悪影響を引き起こす可能性があります。
コストパフォーマンスの高い対策を行うためには、事前準備をしっかりと行い、サービスを熟知することが必要です。
WEBサイトの高負荷対策にお悩みなら、ディーネットへご相談ください。