「社内マニュアルに書いてあるのに答えてくれない」「最新の情報を聞いたのに、なぜか古い内容が返ってくる」——生成AIを業務で使い始めると、こうしたズレに必ずぶつかります。
原因はシンプルで、LLMは“学習済みの公開情報”がベースだからです。ここを補うのがRAG(検索拡張生成)。外部データをその場で読み込ませ、回答精度を引き上げる仕組みです。
本記事では、RAGの基本だけでなく、「どんなときに効くのか/逆に向かないのか」「ファインチューニングとどう使い分けるのか」まで、実務で迷わない形で整理します。
-PR-
【オンデマンド配信】生成AIを業務に組み込む第一歩
~ChatGPTからDifyへ、現場で成果を出す方法~
ChatGPTで“個人の生産性”は向上しているのに、“業務全体の変革”につながらない。その原因は、生成AIが業務フローに組み込まれていないことにあります。
本ウェビナーでは、ディーネットが社内外で実証してきたDifyを軸としたAIワークフロー設計、RAG運用、業務自動化の実例をもとに、生成AIを業務に根付かせるためのステップを体系的に解説します。
> いますぐ視聴する <
1. RAG(Retrieval-Augmented Generation)とは?
RAGは「Retrieval + Augmented Generation」の略で、直訳すると「検索拡張生成」という意味です。
その流れを超シンプルに言うと、次の手順になります。
- ユーザーの質問を受け取る。
- データベースから関連情報を検索する(情報をベクトル化しておく場合が多い)。
- 見つかった関連情報を“コンテキスト”としてLLMに渡す。
- LLMが回答を生成し、ユーザーに返す。

つまり、普段は(公開情報しか知らない)LLMに対して、外部の必要な情報を「一時的に読み込ませる」イメージです。これにより、通常のLLM単体よりも正確かつ自社専用の回答を生成できるようになります。
2. なぜRAGが必要なのか?
LLMは大規模なテキストデータを学習しているため、「一般知識」に関する回答は優れています。しかし、以下のような情報は通常のLLMでは回答が困難です。
- 自社独自の売上や顧客データ
- 最新の業界レポート
- 社内のマニュアルやドキュメント
例えば、社内向けチャットボットに「2024年の第1事業部の売上はどれくらい?」と質問しても、一般公開されていないデータであればLLMは回答できません。
一方、RAGであれば、
- 社内データベースを検索して必要な売上データを取得し、
- そのデータをLLMにコンテキストとして渡して質問に答えさせる
ことができます。
これにより、常に最新かつ正確な情報を踏まえた回答が期待できるのです。
3. RAGの仕組みをもう少し詳しく
ここでは、具体的なチャットボットの例を使って見てみましょう。将棋専用のRAGを組んだ場合で考えてみます。
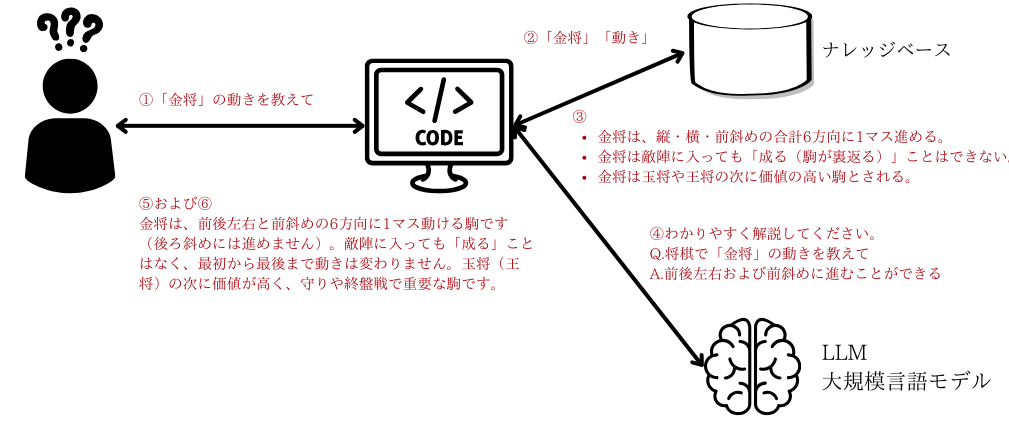
- ユーザーが質問する
- 例:将棋で「金将」の動きを教えて
- 検索エンジン(リトリーバ)によるデータベース検索
- 質問に関連するナレッジベースを探し出す。
- 質問・ドキュメント双方をベクトル化して、類似度が高いデータを複数件取り出す。
- 例:
- 金将は、縦・横・前斜めの合計6方向に1マス進める。
- 金将は敵陣に入っても「成る(駒が裏返る)」ことはできない。
- 金将は玉将や王将の次に価値の高い駒とされる。
など、関連度が高そうな情報を引っ張ってくる。
- 抽出した情報をLLMに投げる
- プロンプト(入力)として、
- ユーザーの質問
- データベースから取得した関連情報
- をまとめてLLMに渡す。
- プロンプト(入力)として、
- LLMが回答を生成
- RAGで渡された社内データをもとに、ユーザーの質問に合った回答を出す。
- 例:「金将は、前後左右と前斜めの6方向に1マス動ける駒です(後ろ斜めには進めません)。敵陣に入っても「成る」ことはなく、最初から最後まで動きは変わりません。玉将(王将)の次に価値が高く、守りや終盤戦で重要な駒です。」
このように、あらかじめ社内データやドキュメントを整理・ベクトル化しておくことがRAG導入の要となります。
4. RAGとファインチューニングの違い
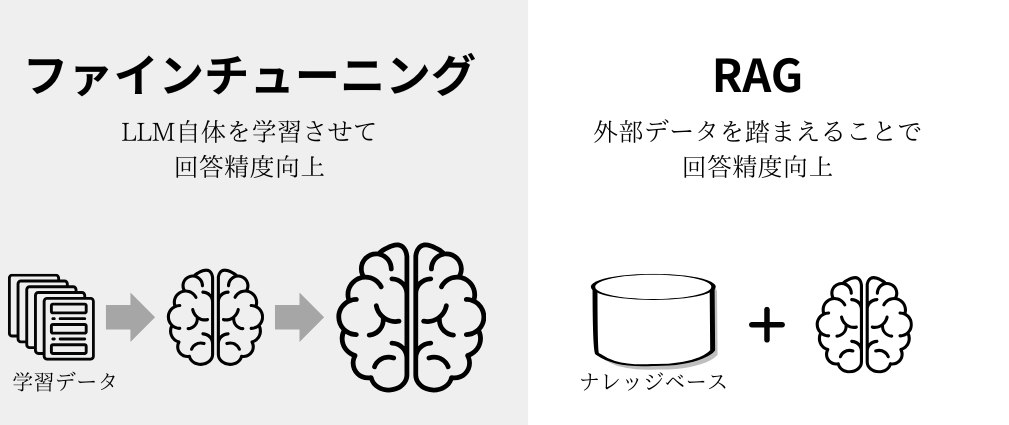
ファインチューニングとは?
- すでに学習済みのLLMに対し、自前のデータセットを使って再学習させるアプローチ。
- 新しいタスク向けにモデルのパラメータ自体を調整するため、それなりの学習コストや専門知識が必要になる。
- ベースモデルを変えるごとに、再度ファインチューニングが必要になる点も手間。
RAGの特徴
- 基本的にモデル自体を再学習する必要がない。
- 必要に応じてデータベース検索で外部データを引っ張ってきて、それをLLMにコンテキストとして渡すだけ。
- 常に最新のモデルや最新のデータベースを組み合わせられる。
- Microsoftの論文でも、ファインチューニングよりRAGの方が精度が高いケースが示唆されている。
どちらを使うべきか?
- 機密情報や独自データに基づく高精度な回答を、常に最新化しながら求めたい場合はRAGがおすすめ。
- 一方で、特定のタスクに特化したモデルを作りたい場合やオフラインでの推論環境が求められる場合などは、ファインチューニングが適するケースもある。
5. RAG導入のポイント
- データの整理・構造化
- 必要なデータをテキスト化しておき、ベクトル化に対応できる形で管理する。
- 文書が乱雑な状態だと正確な検索が難しい。
- 検索ロジック(ベクトル検索)の設定
- 質問と文書を同じ埋め込み空間でベクトル化し、類似度を高い順で検索する仕組みが一般的。
- ベクトル検索エンジン(例:Faiss、Milvus、Elasticsearch+プラグイン など)の利用を検討。
- プロンプト設計
- LLMへの入力(プロンプト)をどのように構築するかで回答品質が左右される。
- 「使用してよいデータ」「回答フォーマット」「口調・文体」など、細かい指定が必要な場合はプロンプトに明記するとよい。
- セキュリティ・権限管理
- 社内の機密情報を含むことも多いので、検索結果として取得できる情報や閲覧権限を厳密に制御する。
関連するFAQ
Q. RAGとは一言でいうと何ですか?
A. LLMに“その場で外部知識を持たせて回答させる仕組み”です。検索した情報を根拠に生成するため、社内データや最新情報を扱えます。
Q. なぜRAGが必要なのですか?
A. LLMは学習済みの公開情報が中心で、非公開データや最新情報には弱いためです。RAGは検索でその不足分を補います。
Q. RAGとファインチューニングの違いは?
A. 一言でいうと「データを差し替えるのがRAG/モデル自体を作り替えるのがファインチューニング」です。前者は柔軟性、後者は特化性能に強みがあります。
Q. どちらを選べばいいですか?
A. 社内データ・最新情報を扱うならRAG。特定タスクに最適化された一貫した振る舞いが必要ならファインチューニングが向いています。
Q. RAGは万能ですか?向いていないケースは?
A. 万能ではありません。例えば以下は不向きです。
・検索対象のデータが未整理/品質が低い場合
・リアルタイム性が極端に高い(秒単位更新など)
・計算・分類など“検索より推論が主役”のタスク
Q. RAGでも間違えるのはなぜですか?
A. 検索で誤った文書を拾う、文書の分割(チャンク)が不適切、プロンプト設計が弱いなどが原因です。「何を渡すか」で精度が大きく変わります。
Q. 導入時によくある失敗は?
A. 典型例は以下です。
・文書を長いまま登録して検索精度が落ちる
・チャンク分割が粗く、必要な情報がヒットしない
・権限設計ミスで見せてはいけない情報が出る
・ベクトル検索だけに頼り、キーワード検索と併用しない
Q. 小規模でもRAGは導入すべきですか?
A. 社内ドキュメントやFAQが一定量あるなら有効です。むしろ小規模な方がデータ整備がしやすく、効果を実感しやすいケースもあります。
Q. ベクトル検索だけで十分ですか?
A. 不十分なことも多いです。キーワード検索とのハイブリッドや再ランキングを組み合わせることで精度が安定します。
7. まとめ
RAG(Retrieval-Augmented Generation)は、外部データベースからの検索結果をLLMに渡すことで、クローズドな独自情報を使った回答を生成できる手法です。ファインチューニングと比べてモデルの再学習が不要なので、最新のモデルと組み合わせて使いやすいのが特徴です。ただし、実運用ではデータ整理・検索ロジック・プロンプト設計など事前準備が大切となります。
RAGを使うことで、一般知識ベースのAIでは難しかった「自社や自組織に特化したチャットボット・検索サービス」が実現可能になります。
一方で、ファインチューニングが活きるシーンもあるため、状況に応じてどちらを採用すべきかを検討してみてください。