売上データの分析に時間がかかり、特定の担当者に依存していませんか。本記事では、既存のS3+Athena環境を前提に、Difyを使って「自然言語→SQL生成→クエリ実行→インサイト抽出」までを一気通貫で自動化した実装事例を紹介します。開発は半日ですが、実運用では手作業3時間かかっていた分析が約5分に短縮されました。あわせて、実際に発生したSQL生成ミスや日本語解釈のズレ、Difyを選定した理由(運用・UI・ワークフロー性)など、再現性のある実装ポイントに踏み込んで解説します。
-PR-
【オンデマンド配信】生成AIを業務に組み込む第一歩
~ChatGPTからDifyへ、現場で成果を出す方法~
ChatGPTで“個人の生産性”は向上しているのに、“業務全体の変革”につながらない。その原因は、生成AIが業務フローに組み込まれていないことにあります。
本ウェビナーでは、ディーネットが社内外で実証してきたDifyを軸としたAIワークフロー設計、RAG運用、業務自動化の実例をもとに、生成AIを業務に根付かせるためのステップを体系的に解説します。
> いますぐ視聴する <
課題と解決策
過去に、Amazon QuickSight+Athena+Amazon S3で売上データの分析基盤を構築したものの、いくつかの課題を抱えていました。Difyを利用することで、その課題の解決策を検証していきました。
課題:
- 分析作業が属人化していた
- データから洞察を得るまでのリードタイムが長かった
- 従来通りExcel等で分析している人もおり、データの分析に多くの時間を要していた
解決策:
- Difyを活用した生成AIベースの売上分析ツールを構築
- 自然言語での問いかけから、インサイトを取得
- データ分析作業の自動化と効率化を実現
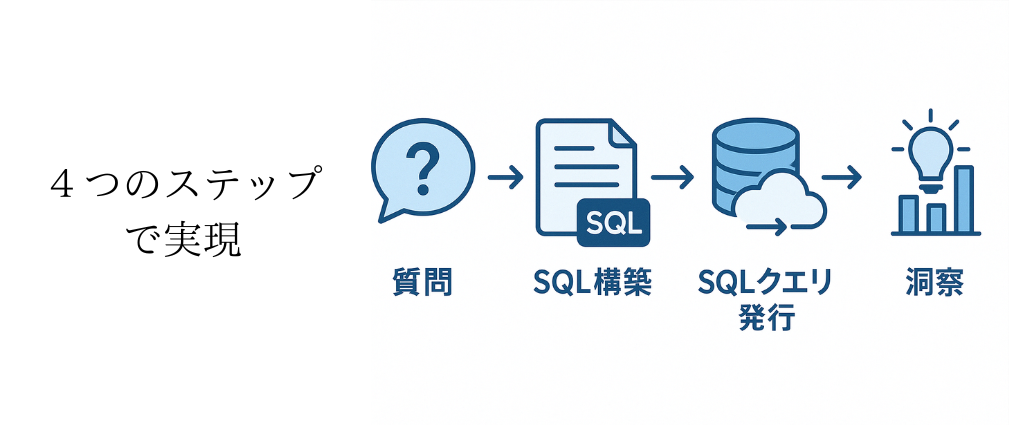
システム構成
システム全体のアーキテクチャは次の通りです。データソースであるS3とAthenaの環境はすでに構築済みでした。そのため、今回は、ユーザーインタフェース部分と処理フロー部分を構築しています。
全体アーキテクチャ
- データソース: Amazon S3に売上データをCSV形式で保管
- ユーザーインターフェース: Difyのチャットインターフェース
- 処理フロー:
- ユーザーが自然言語で質問
- 生成AI(LLM)が質問内容からSQLを自動構築
- API Gateway経由でLambdaがAthenaにクエリを発行
- クエリ結果をもとにAIが分析を実施し回答

Difyアプリケーション構築
Difyではワークフローを活用して以下の処理を実装しています。
1. 質問の明確化
ユーザーからの曖昧な質問を明確化し、SQL構築に適した形に変換します。例えば「先月の売上は?」という質問を「2025年3月の全製品の売上合計を教えてください」のように具体化します。
2. SQL構築
明確化された質問からAthena用のSQLを自動生成します。ここでは以下のような技術的課題に対処しました。
- AthenaのPrestoベースのSQL構文への対応
- 日本語のエイリアス名のダブルクォーテーション処理
- 改行やコードスニペット情報の適切な処理
3. SQLクエリ発行
構築したSQLをAPI Gateway経由でLambda関数に渡し、Athenaでクエリを実行します。これによりS3上のデータに対して効率的な分析が可能になります。
4. 回答生成
クエリ結果と元の質問内容を照らし合わせ、ビジネス的な洞察を含む最適な回答を生成します。単なる数値の羅列ではなく、トレンドや異常値の指摘なども行います。
回答できる内容の例
このツールでは、以下のような質問に回答可能です。
- 「初期費用と月額料金の推移を教えて」
- 「2025年2月と3月の売上を比較して」
- 「株式会社○○のサービスごとの売り上げ推移を取得して」
- 「顧客セグメント別の売上構成比はどうなっている?」
- 「昨年同期比でどのサービスが最も成長している?」
導入効果
- 時間削減:
いままで、数時間かかってExcel等を駆使して分析していた作業が数分に短縮されました。 - アクセシビリティ向上:
過去にも売上データは分析用にS3へ保存し、Athenaでクエリできるようになっていましたが、SQLを書ける一部の担当者しか利用ができていませんでした。しかしながら、SQLを書けない担当者でもデータ分析が手軽に利用できるようになりました。 - 意思決定の迅速化:
少し気になったことを数秒で確認できるので、データに基づく判断をより早く行えるようになりました。 - 分析の質向上:
AIによる多角的な視点から分析をすることで、手動では気づかなかった分析結果を確認することができています。
関連するFAQ
Q. Difyで何が自動化されるのですか?
A. 自然言語の質問を具体化し、Athena用SQLを生成、API経由でクエリ実行、結果の要約とインサイト提示までを一連で自動化します。
Q. SQLが間違って生成されることはありますか?
A. あります。例えば「先月」を誤って直近30日と解釈し月次集計がズレる、JOIN条件が不足して重複集計になる、といったケースが発生しました。対策として、質問の明確化ステップで日付粒度を固定化し、テーブル定義とJOINルールをプロンプトに明示することで改善しています。
Q. 具体的な入出力のイメージは?
A. 例:入力「2025年2月と3月の売上を比較して」
生成SQL(抜粋)「SELECT month, SUM(amount) FROM sales WHERE month IN (‘2025-02′,’2025-03’) GROUP BY month」
出力「3月は2月比で+18%。特にサブスクリプションが伸長」
このように質問→SQL→要約までが自動で返ります。
Q. なぜDifyを選んだのですか?
A. ワークフローとして「質問明確化→SQL生成→実行→要約」を分離・可視化でき、非エンジニアでも運用しやすいためです。コード中心の構成よりも、プロンプト調整や改善サイクルを現場で回しやすい点を重視しました。
Q. 既存のデータ基盤がないと使えませんか?
A. 本事例はS3+Athena前提ですが、データレイク+クエリエンジンの構成であれば応用可能です。今回はUIと処理フローをDifyで補っています。
Q. 導入効果はどの程度ですか?
A. 代表的な分析作業は約3時間→約5分に短縮。SQLが書けないメンバーも利用可能になり、日次の確認クエリ回数も増え、意思決定のスピードが向上しました。
Q. コストはどのくらいかかりますか?
A. 主にAthenaのクエリ課金とLLM利用料です。クエリのスキャン量を抑える(パーティション設計、列絞り込み)ことでコストは大きく変わります。頻繁に使う集計は事前集約テーブルで最適化すると安定します。
Q. この構成の限界はありますか?
A. 複雑な多段JOINや業務固有ロジックは誤生成が増えやすく、データ品質にも強く依存します。重要指標は検証用クエリを別途用意するなど、完全自動化にしすぎない設計が必要です。
Q. どのような質問に対応できますか?
A. 月次推移、期間比較、顧客・サービス別売上、構成比、前年同期比など、一般的な売上分析に対応できます。
まとめ
Difyを活用した売上分析ツールの構築は、半日程度という短期間で実現できました。生成AIの力を借りることで、データ分析の民主化と効率化を同時に達成できます。SQLの知識がなくても、自然言語で質問するだけでデータから洞察を得られるツールは、ビジネスの意思決定スピードを大幅に向上させます。
今後はさらに機能を拡充し、予測分析や異常検知などの高度な分析も可能にしていく予定です。Difyの柔軟性を活かし、ビジネスニーズに合わせた拡張を続けていきます。