監視とは

監視とは
監視は
・定期的なデータ収集
・収集したデータの保管
・保管したデータの可視化
・保管したデータの分析およびレポート
・アラート通知
など、様々な機能で構成されています。
AWSでは、「CloudWatch」が監視系のサービスとして知られています。
しっかりと監視設計を行い、CloudWatch含め適材適所でツールを利用していくことが求められます。
主な監視の種類

監視の種類
代表的な3つ監視の種類について解説します。
・アプリケーション監視
・サーバー監視
・AWS基盤監視
■アプリケーション監視
アプリケーションのメトリクスやログの監視を行います。メトリクスとは、応答速度などの定量的なデータのことです。アプリケーションのパフォーマンスや異常予兆を把握し、トラブルシューティングに活用します。
■サーバー監視
CPUやメモリ、ディスクなどのOSに関するメトリクスの監視を行います。また、WEBサーバーやDBサーバー固有のメトリクスやログについても行います。
■AWS基盤監視
CPUクレジットやディスクIOなど、AWS基盤固有のメトリクスについての監視を行います。
AWSでは「CloudWatch」を活用
AWSではCloudWatchを活用
AWSでは、監視関連のサービスとして「CloudWatch」が提供されています。
CloudWatchでは、AWS基盤のメトリクスの収集やグラフ化、異常検知が可能です。カスタマイズすることで、サーバーのメトリクスの取得も可能です。
SNS(AWS Simple Notification Service)と連携することで、通知も行うことができます。
CloudWatchはセルフサービスで利用することができ、様々なサービスと組み合わせることができます。
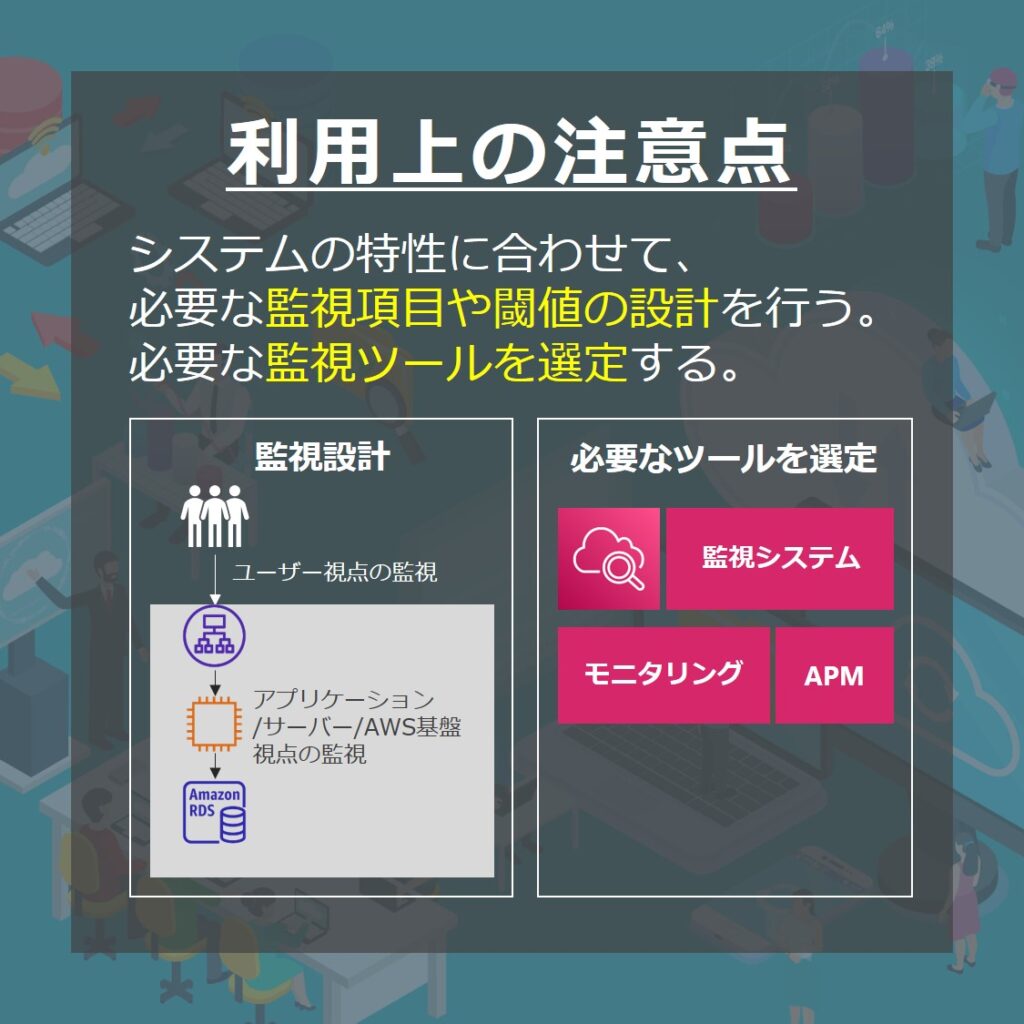
自社で監視を行う場合の注意事項
自社で監視を行う場合の注意事項
監視はシステムの特性に合わせて行うことが重要です。
必要な監視項目や適切な設定値はシステムによって異なります。まず、監視についての設計を行いましょう。特にユーザー視点で監視を行うことが重要です。
設計によって必要な監視が決まったら、ツール選びが重要になります。
2000年代前後まではNagiosという監視ツール1つで賄うことができていました。しかし、現在は必要な監視ツールを組み合わせて利用することが求められています。
AWS基盤の情報を監視するツール、サーバー内部を監視するツール、グラフ化ツールやアプリケーションのパフォーマンスを監視ツールなど、様々なものを組み合わせて利用します。
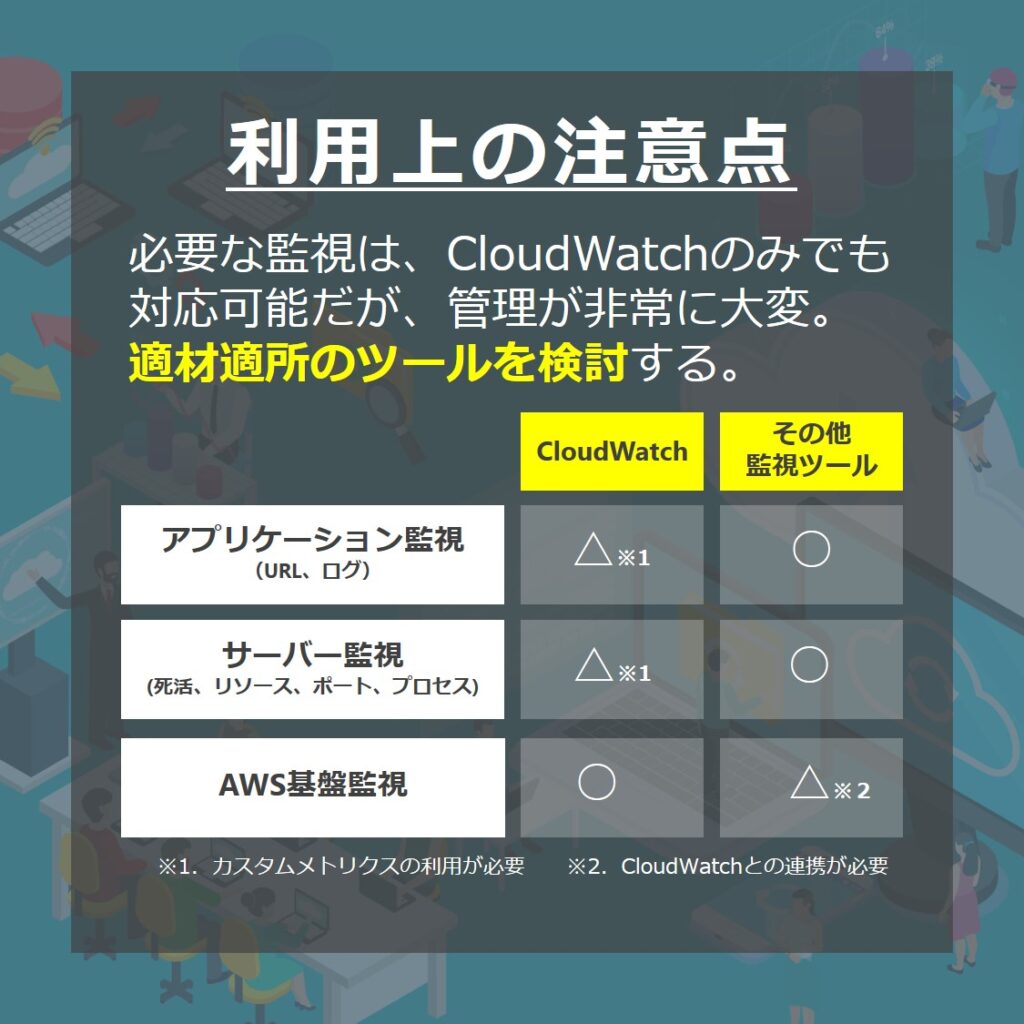
CloudWatch利用上の注意事項
CloudWatchを利用する場合は、利用範囲に注意が必要です。
CloudWatchで標準的に取得できるのはAWS基盤の情報となります。カスタムメトリクスを利用することで、サーバー内部の情報やアプリケーションの情報などの取得ができるようになります。取得はできますが、設定や管理が煩雑になり大変です。
逆に一般的な監視ツールでは、サーバー内部の情報やアプリケーションの情報は取得できますが、AWS基盤の情報取得ができません。
CloudWatchだけ使う、一般的な監視ツールだけ使う。のではなく、必要な部分を組み合わせて使うことが必要です。
ディーネットのAWS運用代行サービスでは

ディーネットのAWS運用代行サービスでは
ディーネットでは、AWSの運用代行サービスを提供しています。
お客様に、細かいAWSの技術知識は不要です。
運用対象のサービスやシステムの特性をお教えください。弊社にてサービス特性に応じた監視設計をいたします。また、最適なツールを使った監視の提供を行います。
監視以外の運用についてもお任せいただけます。
関連するFAQ
Q. 監視にはどんな機能が含まれますか?
A. データの収集・保管・可視化・分析・レポート・アラート通知で構成されます。重要なのは「異常を検知して通知するところまで含めて設計する」点です。
Q. AWSではCloudWatchだけで十分ですか?
A. AWS基盤の監視には有効ですが、以下の課題が出やすいです。
・カスタムメトリクス増加によるコスト増
・ログからメトリクス化する手間
・アプリケーション単位の可視化が弱い
・アラートが増えすぎて運用が崩壊
そのため、用途を限定し他ツールと併用するのが現実的です。
Q. 監視の種類はどう分けて考えればいいですか?
A. 「アプリケーション監視」「サーバー監視」「AWS基盤監視」の3つに分けます。
例えば、レスポンスタイムやエラー率はアプリ、CPUやメモリはサーバー、CPUクレジットやEBS I/OはAWS基盤といった具合に役割が異なります。
Q. 監視設計はどのように進めればよいですか?
A. 次の手順で進めるとブレません。
1. 監視目的の定義(可用性・性能・コスト)
2. SLI/SLOの設定(例:成功率99.9%、応答200ms以内)
3. 監視対象の分解(アプリ/サーバー/AWS基盤)
4. ツール選定(役割ごとに分ける)
5. アラート設計(通知条件・優先度・運用フロー)
Q. ユーザー視点の監視とは何ですか?
A. システム内部の数値ではなく、ユーザー体験に直結する指標を重視する考え方です。
具体的には「レスポンスタイム」「エラー率」「成功率」などで、CPUが正常でもユーザーが遅いと感じれば問題と捉えます。
Q. ツールの組み合わせ例を教えてください
A. 代表的な構成は以下です。
・CloudWatch + Datadog
→ AWS基盤はCloudWatch、アプリ/可視化はDatadog
・CloudWatch + Prometheus + Grafana
→ メトリクス収集はPrometheus、可視化はGrafana、基盤はCloudWatch
単一ツールで完結させるより、役割分担する方が運用しやすくなります。
Q. よくある監視の失敗は何ですか?
A. 典型的には次の通りです。
・アラートが多すぎて誰も見なくなる
・CPUなどインフラ指標だけ見て障害を見逃す
・閾値が適当で誤検知/見逃しが多発
・設計せずにツール導入して後から破綻
設計と運用ルールを先に決めることが重要です。
Q. CloudWatchを使う際の現実的な役割は?
A. 「AWS基盤の監視とアラートの基盤」として割り切るのが現実的です。アプリケーションの詳細監視や高度な可視化は他ツールに任せることで、運用負荷とコストを抑えられます。
まとめ

最後までご覧いただきありがとうございます
この記事では監視ついて解説しました。
監視では、定期的なデータ収集・保管・可視化・分析・アラートなど様々なことを行います。対象システムに必要な監視設計を行い、適切なツールを組み合わせて選択する必要があります。
AWSではCloudWatchを使うことで、AWS基盤の監視を簡単に行うことが可能です。ただし、全てをCloudWatchで対応しようとすると、管理が煩雑になってしまいます。最適なツールを組み合わせて利用するように心がけましょう。